
Character Encoding
Objectives
- To understand what a character set is
- Explain how characters are represented using ASCII
- Understand how character codes are grouped
- Explain the difference between ASCII and UNICODE
When a user types a key on the keyboard a character is transferred to the computer. As we've seen all our data has to be represented in binary so when the computer receives that character it actually receives a number. That number is a code that stands for the character being sent. every character will have a corresponding code. The codes used is known as the character set.
There are two character sets to consider:
- ASCII: American Standard Code for Information Interchange
- Unicode
ASCII
ASCII is the widely used encoding standard. First published back in 1963. It represents characters using 7 bits, allowing for \(2^7\) or \(128\) different characters. This is enough for all the characters on a standard keyboard with a few codes left over for other purposes.
It includes:
- the digits: '0' - '9'
- lower case letters: 'a' - 'z'
- upper case letters: 'A' - 'Z'
- punctuation symbols: ';', '*', '?', '@', '!' etc..
- non-printing control codes: most of these are now obsolete with a couple of exceptions e.g. TAB, CR, LF
It was originally devised as a standardised coding scheme for text. Messages could be sent between computers and other telecommunication devices that all machines could interpret the text using a standard conversion format. There had been other attempts e.g. EBCDIC which itself was an extension of Binary Coded Decimal developed by IBM in the early 1960s.
Take a look at the ASCII table printed below:
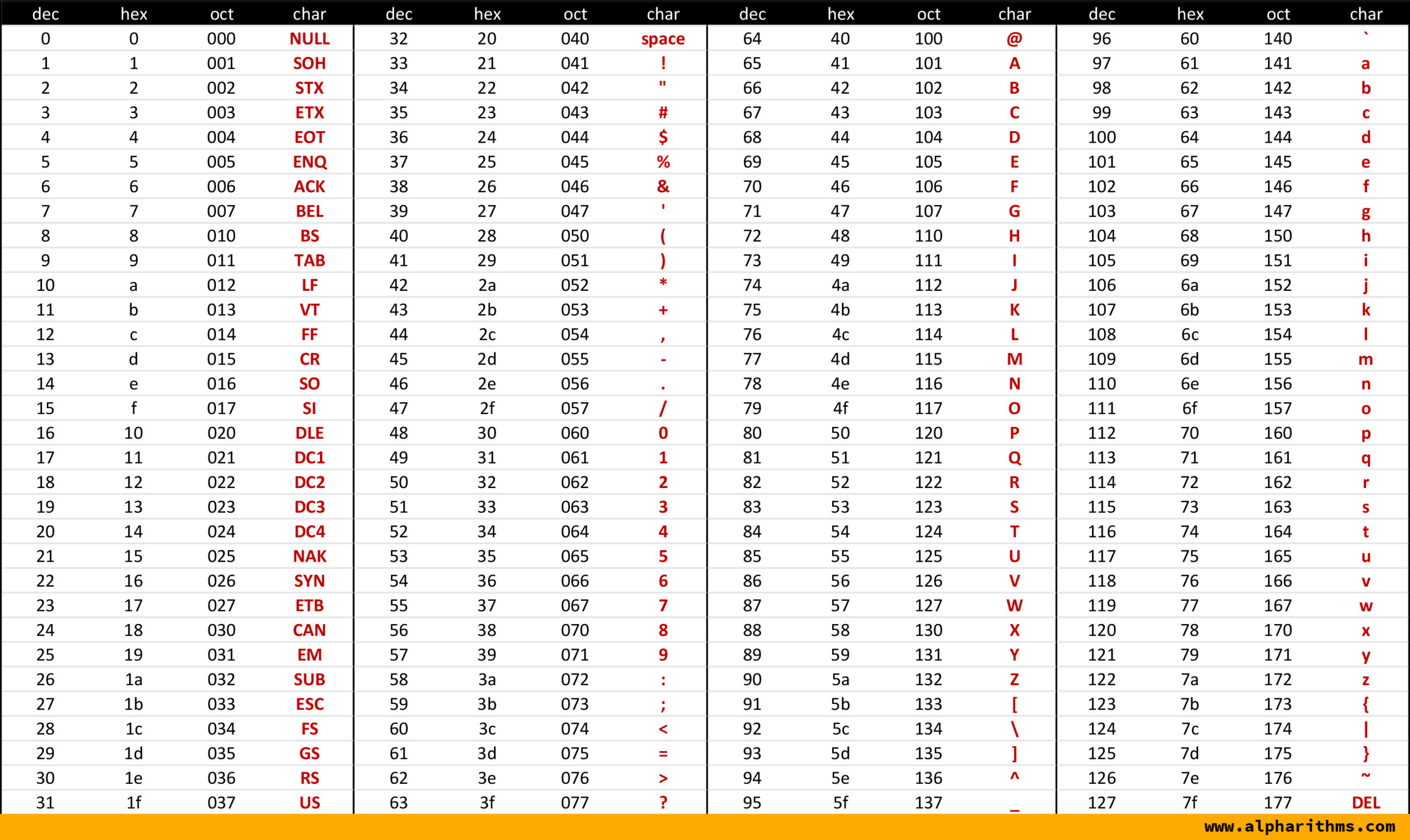
The grouping of letters, numbers and punctuation might appear on first look to be a bit random but there is a beautiful logic behind this grouping.
Start with the numbers:
| Character | Decimal | Hexadecimal | Binary |
|---|---|---|---|
| '0' | 48 | 30 | 0110000 |
| '1' | 49 | 31 | 0110001 |
| '2' | 50 | 32 | 0110010 |
| '3' | 51 | 33 | 0110011 |
| '4' | 52 | 34 | 0110100 |
| .. | .. | .. | .. |
If we "strip off" the leading 3 bits of the binary code we are left with the binary value for that character. Neat? By "strip off" we mean turn those leading 1s into 0s. This can be done by subtracting \(48\) from the character code:
Note
When writing out characters, or strings of characters ALWAYS use quotes. This way it is easy to distinguish between, e.g., the character '5' and the value \(5\).
We'll see something similar when comparing the lower and upper case characters:
| Character | Decimal | Hexadecimal | Binary |
|---|---|---|---|
| 'A' | 65 | 41 | 1000001 |
| 'B' | 66 | 42 | 1000010 |
| 'C' | 67 | 43 | 1000011 |
| .. | .. | .. | .. |
| 'a' | 97 | 61 | 1100001 |
| 'b' | 98 | 62 | 1100010 |
| 'c' | 99 | 63 | 1100011 |
| .. | .. | .. | .. |
A lower case character and its upper case equivalent differs only by one bit, in the \(2^5\) position. Therefore, to convert between lower and upper case characters we just need to flip the bit in that position. Applying the XOR logical operator will do this for us:
Note
XOR stands for "eXclusive OR," and it is a logical binary operation. The XOR operation returns true (or 1) only one of the input bits is set to true (or 1)
ASCII and Python
We can use some built-in functions in Python to explore the ASCII encoding system:
7-bit ASCII
Use ord() to return the ASCII code for a given character:
Use chr() to return the ASCII character for a given code:
Convert character digit to value
Extended ASCII
Standard ASCII uses 7 bits to represent each character, allowing for a total of 128 different characters. However, the limitations of standard ASCII became apparent as computer systems expanded and the need for additional characters, symbols, and language support arose.
Note
Standard ASCII does not include symbols for e.g. '£' and '€', nor any accented characters for languages such as French or German.
To address these limitations, extended ASCII was introduced, which uses 8 bits (1 byte) to represent each character. This extension allows for a total of 256 possible characters, doubling the capacity of standard ASCII. The additional 128 characters are used to include special characters, accented letters, symbols, and characters from various languages.
The first 128 characters in extended ASCII remain the same as standard ASCII, ensuring backward compatibility. The extended range (128-255) varies across different implementations and may include characters specific to certain languages, symbols, or additional graphical elements.
It's important to note that the term "extended ASCII" does not refer to a single universally accepted standard. Different systems and applications might use different extended ASCII sets, leading to compatibility issues which Unicode addressed.
Unicode
Unicode is a more extensive character encoding system that overcomes the limitations of ASCII and Extended ASCII. It uses a variable number of bits for each character, typically 8, 16, or 32 bits. Unicode aims to provide a universal character set to support all languages and symbols worldwide. Unicode assigns a unique code point to each character, it can produce over a million code points which is more than enough for every character in every language.
Unicode is now the universal standard system for encoding characters - even emojis are included!
The codes are grouped in tables, and it extends far beyond the 128 characters of ASCII but it utilizes the same codes as ASCII for the first 127 characters. This ensures that text encoded in ASCII can be seamlessly interpreted as Unicode, simplifying the transition and compatibility between the two standards.
When working with the web, HTML and also Python programming you'll encounter the UTF-8 encoding standard. Unicode alone doesn’t store words in binary. Computers need a way to translate Unicode into binary so that its characters can be stored in text files. This the role of UTF-8. UTF stands for Unicode Transformation Format, it translates any Unicode character to a matching unique binary string and vice versa.